| config | ||
| custom_datasets | ||
| features | ||
| misc | ||
| models | ||
| processed | ||
| raw_data | ||
| runners | ||
| .gitattributes | ||
| generate_parallel_avsd.sh | ||
| generate_parallel_nextqa.sh | ||
| init_utils.py | ||
| LICENSE | ||
| main.py | ||
| merge_pred_avsd.py | ||
| merge_pred_nextqa.py | ||
| optim_utils.py | ||
| README.md | ||
MST-MIXER  : Multi-Modal Video Dialog State Tracking in the Wild
: Multi-Modal Video Dialog State Tracking in the Wild
Adnen Abdessaied, Lei Shi, Andreas Bulling
ECCV 2024, Milan, Italy 
[Paper]
Citation
If you find our code useful or use it in your own projects, please cite our paper:
@InProceedings{Abdessaied_2024_eccv,
author = {Abdessaied, Adnen and Shi, Lei and Bulling, Andreas},
title = {{Multi-Modal Video Dialog State Tracking in the Wild}},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2024}
}
Table of Contents
Setup and Dependencies
We implemented our model using Python 3.7 and PyTorch 1.12.0 (CUDA 11.3, CuDNN 8.3.2). We recommend to setup a virtual environment using Anaconda.
- Install git lfs on your system
- Clone our repository to download a checpint of our best model and our code
git lfs install git clone this_repo.git - Create a conda environment and install dependencies
conda create -n mst_mixer python=3.7 conda activate mst_mixer conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch conda install pyg -c pyg conda install pytorch-scatter -c pyg # pytorch >= 1.8.0 conda install pytorch-sparse -c pyg # pytorch >= 1.8.0 conda install -c huggingface transformers pip install evaluate wandb glog pyhocon attrs
Download Data
AVSD
- Download the AVSD-DSTC7, AVSD-DSTC8 and AVSD-DSTC10 data
- Place the raw json files in
raw_data/and the features infeatures/ - Prepeocess and save the input features for faster training as indicated in
custom_datasets/
NExT-QA
- For convenience, we included the features/data in this git repo.
Training
We trained our model on 8 Nvidia Tesla V100-32GB GPUs. The default hyperparameters in config/mst_mixer.conf need to be adjusted if your setup differs from ours.
AVSD
- Set
task=avsdinconfig/mst_mixer.conf -
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python main.py \ --mode train \ --tag mst_mixer_avsd \ --wandb_mode online \ --wandb_project mst_mixer_avsd
To deactivate wandb logging, use --wandb_mode disabled.
On a similar setup to ours, this will take roughly 20h to complete.
NExT-QA
- Set
task=nextqainconfig/mst_mixer.conf -
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python main.py \ --mode train \ --tag mst_mixer_nextqa \ --wandb_mode online \ --wandb_project mst_mixer_nextqa
Response Generation
AVSD-DSTC7
- Set
dstc=7in the.conffile of your trained networks. in The default setting, can find this underlogs/unique_training_tag/code/config/mst_mixer.conf - Generate the responses
./generate_parallel_avsd.sh mst_mixer/mixer results_avsd_dstc7 generate logs/mst_mixer_avsd 7
- All responses will be saved in
output/dstc7/
AVSD-DSTC8
- Set
dstc=8in the.conffile of your trained networks. in The default setting, can find this underlogs/unique_training_tag/code/config/mst_mixer.conf - Generate the responses
./generate_parallel_avsd.sh mst_mixer/mixer results_avsd_dstc8 generate logs/mst_mixer_avsd 8
- All responses will be saved in
output/dstc8/
AVSD-DSTC10
- Set
dstc=10in the.conffile of your trained networks. in The default setting, can find this underlogs/unique_training_tag/code/config/mst_mixer.conf - Generate the responses
./generate_parallel_avsd.sh mst_mixer/mixer results_avsd_dstc10 generate logs/mst_mixer_avsd 10
- All responses will be saved in
output/dstc10/
NExT-QA
- Generate the responses
./generate_parallel_nextqa.sh mst_mixer/mixer results_nextqa generate logs/mst_mixer_nextqa
- All responses will be saved in
output/nextqa/ - Evalute using this script
Results
To evaluate our best model on
AVSD-DSTC7
Executing the eval_tool of AVSD-DSTC7 using the generated repsonses will output the following metrics
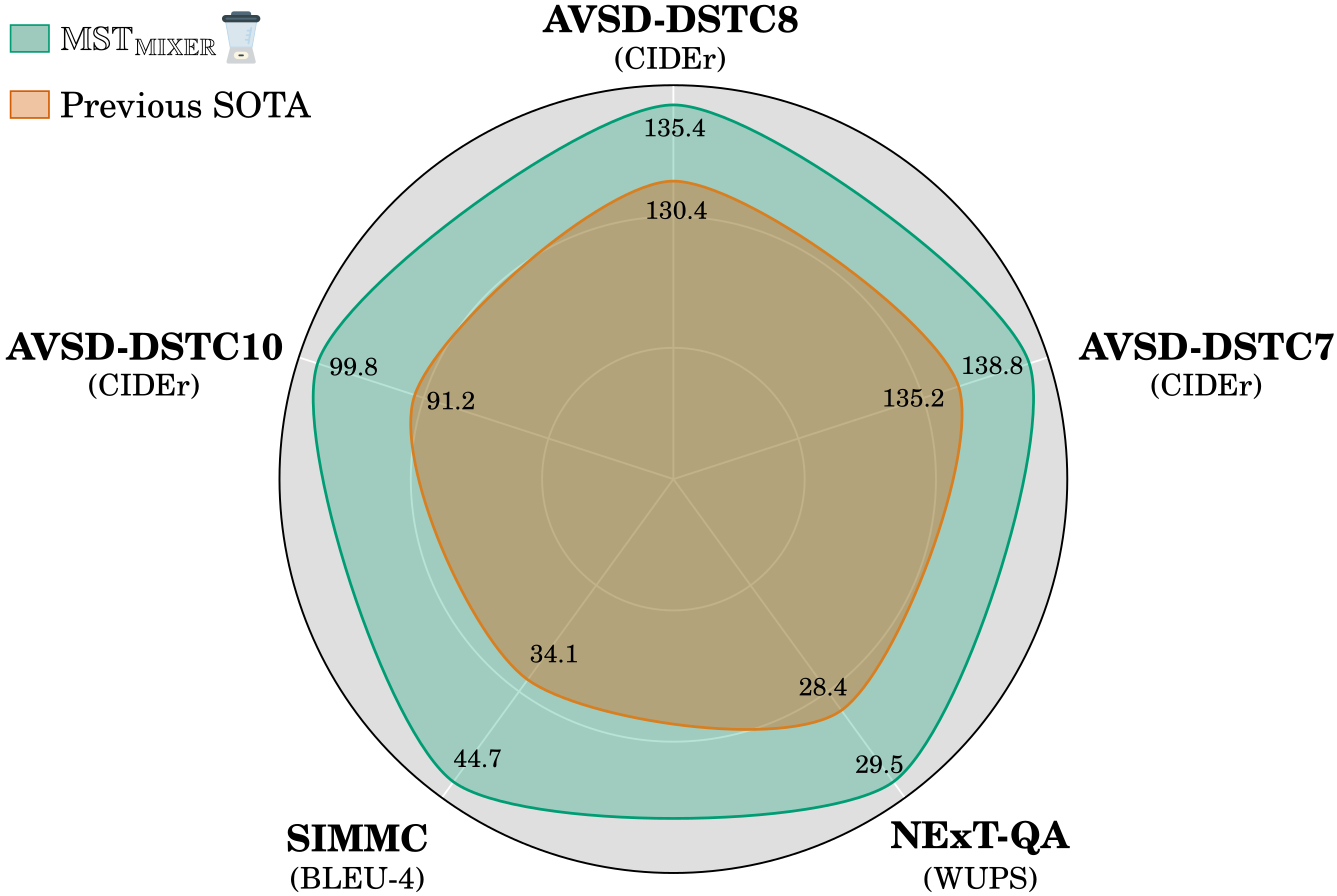
| Model | BLUE-1 | BLUE-2 | BLUE-3 | BLUE-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|
| Prev. SOTA | 78.2 | 65.5 | 55.2 | 46.9 | 30.8 | 61.9 | 135.2 |
| MST_MIXER | 78.7 | 66.5 | 56.3 | 47.6 | 31.3 | 62.5 | 138.8 |
AVSD-DSTC8
- Set
dstc=8in theckpt/code/mst_mixer.conf - run
./generate_parallel_avsd.sh mst_mixer/mixer results_avsd_dstc8_best_model generate ckpt/avsd 8
- The responses will be saved in
output/dstc8/ - Executing the eval_tool of AVSD-DSTC8 using the generated repsonses will output the following metrics
| Model | BLUE-1 | BLUE-2 | BLUE-3 | BLUE-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|
| Prev. SOTA | 76.4 | 64.1 | 54.3 | 46.0 | 30.1 | 61.0 | 130.4 |
| MST_MIXER | 77.5 | 66.0 | 56.1 | 47.7 | 30.6 | 62.4 | 135.4 |
AVSD-DSTC10
Executing the eval_tool of AVSD-DSTC10 using the generated repsonses will output the following metrics
| Model | BLUE-1 | BLUE-2 | BLUE-3 | BLUE-4 | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|---|
| Prev. SOTA | 69.3 | 55.6 | 45.0 | 37.2 | 24.9 | 53.6 | 91.2 |
| MST_MIXER | 70.0 | 57.4 | 47.6 | 40.0 | 25.7 | 54.5 | 99.8 |
NExT-QA
Executing the eval script of NExT-QA using the generated repsonses will output the following metrics
| Model | WUPS_C | WUPS_T | WUPS_D | WUPS |
|---|---|---|---|---|
| Prev. SOTA | 17.98 | 17.95 | 50.84 | 28.40 |
| MST_MIXER | 22.12 | 22.20 | 55.64 | 29.50 |
Acknowledgements
We thank the authors of RLM for providing their code that greatly influenced this work.