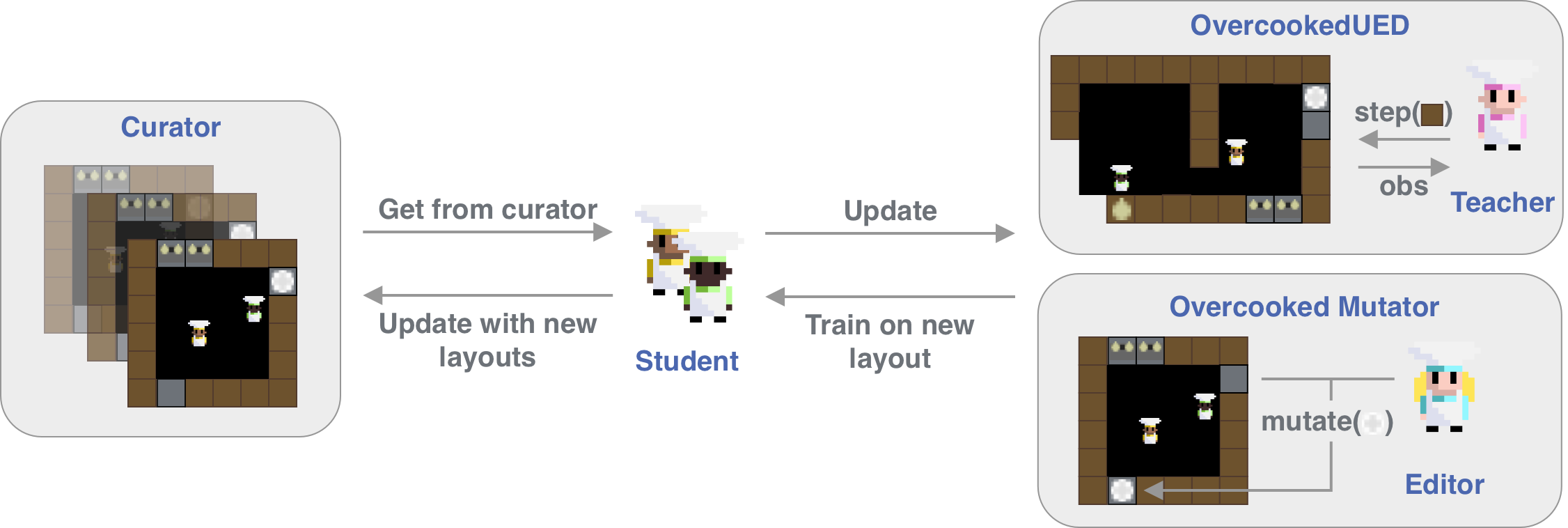
This repository houses the Overcooked generalisation challange, a novel cooperative UED environment that explores the effect of generalisation on cooperative agents with a focus on zero-shot cooperation.
We built this work on top of [minimax](https://github.com/facebookresearch/minimax) (original README included below) and are inspired by many of their implementation details.
We require Python to be above 3.9 and below 3.12, we use 3.10.12.
To install this research code use `pip install -r requirements.txt`.
## Structure
Our project inlcudes the following major components:
- Overcooked UED
- Multi-Agent UED Runners
- Scripts for training and evaluations
- Holdout populations for evaluation (accesible [here](https://drive.google.com/drive/folders/11fxdhrRCSTmB7BvfqMGqdIhvJUDv_0zP?usp=share_link))
We highlight our additions to minimax below often with additional comments.
We choose minimax as the basis as it is tested and intended for this use case.
The project is structured as follows:
```
docs/
envs/
...
overcooked.md (<- We document OvercookedUED here)
images/
...
examples/*
src/
config/
configs/
maze/*
overcooked/* (<- Our configurations for all runs in the paper)
minimax/
agents/
...
mappo.py (<- Our MAPPO interface for training)
config/* (<- logic related to configs, and getting commands, OvercookedUED included)
envs/
...
overcooked_proc/ (<- home of overcooked procedual content generation for UED)
...
overcooked_mutators.py (<- For ACCEL)
overcooked_ood.py (<- Testing layouts (can be extended!))
overcooked_ued.py (<- UED interface)
overcooked.py (<- Overcooked capable of being run in parallel across layouts)
models/
...
overcooked/
...
models.py (<- Models we use in the paper are defined here)
runners/*
runners_ma/* (<- multi-agent runners for Overcooked UED and potentially others)
tests/*
utils/*
arguments.py
count_params.py
evaluate_against_baseline.py
evaluate_against_population.py
evaluate_baseline_against_population.py
evaluate_from_pckl.py
evaluate.py
extract_fcp.py
train.py (<- minimax starting point, also for our work)
populations/
fcp/* (see below)
baseline_train__${what} (Trains multiple self play agents across seeds)
eval_xpid_${what} (Evals populations, stay and random agents)
eval_xpid.sh (Evals a run based on its XPID)
extract_fcp.sh (Extracts FCP checkpoint from self-play agents)
make_cmd.sh (Extended with our work)
train_baseline_${method}_${architecture}.sh (Trains all methods in the paper)
train_maze_s5.sh
train_maze.sh
```
## Overcooked UED
We provide a detailed explanation of the environment in the paper.
OvercookedUED provides interfaces to both edit-based, generator-based and curator-based DCD methods.
For an overview see the figure above.
## Mutli-Agent UED Runners
Multi-Agent runners are placed under `src/minimax/runners_ma`.
They extend the minimax runners by support for multiple agents, i.e. by carrying around hidden states etc.
Note: Our current implementation only features two agents.
## Scripts
Reproducability is important to us.
We thus store all important script in this repository that produce the policies discussed in the paper.
To generate a command, please use `make_cmd.sh` like so by specifying `overcooked` and the config file name:
```bash
> ./make_cmd.sh overcooked baseline_dr_softmoe_lstm
python -m train \
--seed=1 \
--agent_rl_algo=ppo \
--n_total_updates=30000 \
--train_runner=dr \
--n_devices=1 \
--student_model_name=default_student_actor_cnn \
--student_critic_model_name=default_student_critic_cnn \
--env_name=Overcooked \
--is_multi_agent=True \
--verbose=False \
--log_dir=~/logs/minimax \
--log_interval=10 \
--from_last_checkpoint=False \
...
```
They are named `train_baseline_${method}_${architecture}.sh` and can be found in `src`.
`${method}` specifies the DCD method and can be from {`p_accel`, `dr`, `pop_paired`, `p_plr`} which correspond to parallel ACCEL (https://arxiv.org/abs/2203.01302 & https://arxiv.org/abs/2311.12716), domain randimisation (https://arxiv.org/abs/1703.06907), population paired (https://arxiv.org/abs/2012.02096) and parallel PLR (https://arxiv.org/abs/2010.03934 & https://arxiv.org/abs/2311.12716).
`${architecture}` on the other hand corresponds to the neural network architechture employed and can be from {`lstm`, `s5`, `softmoe`}.
To use them, please set the environment variable `${WANDB_ENTITY}` to your wandb user name or specify `wandb_mode=offline`.
The scripts can be called like this:
```bash
./train_baseline_p_plr_s5.sh $device $seed
```
The scripts run `src/minimax/train.py` and store their results to the configured locations (see the config jsons and the `--log_dir` flag) but usually somewhere in your home directory `~/logs/`.
There are 12 train scripts and helper scripts that run multiple variations of these after the other, i.e. like in `train_baselines_s56x9.sh` that trains all 4 DCD methods with an S5 policy:
```bash
DEFAULTVALUE=4
DEFAULTSEED=1
device="${1:-$DEFAULTVALUE}"
seed="${2:-$DEFAULTSEED}"
echo "Using device ${device} and seed ${seed}"
./train_baseline_p_plr_s5.sh $device $seed
./train_baseline_p_accel_s5.sh $device $seed
./train_baseline_pop_paired_s5.sh $device $seed
./train_baseline_dr_s5.sh $device $seed
```
Evaluation is performed via scripts starting with `eval`.
One can evaluate against scripted agents `eval_stay_against_population.sh` and random ones via `eval_random_against_population.sh`.
To evaluate against a population using a trained agent use `eval_xpid_against_population.sh` with device 4 and the agents XPID `YOUR_XPID` you can use `./eval_xpid_against_population.sh 4 YOUR_XPID`.
## Holdout populations for evaluation
The populations can be accessed here: https://drive.google.com/drive/folders/11fxdhrRCSTmB7BvfqMGqdIhvJUDv_0zP?usp=share_link.
They need to be placed under `src/populations` to work with the provided scripts.
Alternatively -- if desired -- populations can be obtained by running `src/baseline_train__all.sh` or alternatively by using `src/baseline_train__8_seeds.sh` for the desired layout, i.e. via:
```bash
./baseline_train__8_seeds.sh $device coord_ring_6_9
```
We exclude the detailed calls here as they are too verbose.
The resulting directory structure for inlcuding the poppulations should look like the following:
```txt
src/
minimax
...
populations/
fcp/
Overcooked-AsymmAdvantages6_9/
1/
high.pkl
low.pkl
meta.json
mid.pkl
xpid.txt
2/*
...
8/*
population.json
Overcooked-CoordRing6_9/*
Overcooked-CounterCircuit6_9/*
Overcooked-CrampedRoom6_9/*
Overcooked-ForcedCoord6_9/*
```
To work with these populations meta files point to the correct scripts.
These are included in the downloadable zip, called `population.json` (see above) and should look like this:
```json
{
"population_size": 24,
"1": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/low.pkl",
"2": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/mid.pkl",
...
"24": "populations/fcp/Overcooked-AsymmAdvantages6_9/8/high.pkl",
"1_meta": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/meta.json",
"2_meta": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/meta.json",
...
"24_meta": "populations/fcp/Overcooked-AsymmAdvantages6_9/8/meta.json"
}
```
They help our evaluation to keep track of the correct files to use.
To check whether they work correctly use something along the lines of (compare the eval scripts):
```bash
DEFAULTVALUE=4
device="${1:-$DEFAULTVALUE}"
for env in "Overcooked-CoordRing6_9" "Overcooked-ForcedCoord6_9" "Overcooked-CounterCircuit6_9" "Overcooked-AsymmAdvantages6_9" "Overcooked-CrampedRoom6_9";
do
CUDA_VISIBLE_DEVICES=${device} LD_LIBRARY_PATH="" nice -n 5 python3 -m minimax.evaluate_baseline_against_population \
--env_names=${env} \
--population_json="populations/fcp/${env}/population.json" \
--n_episodes=100 \
--is_random=True
done
```
## Credit the minimax authors
For attribution in academic contexts please also cite the original work on minimax:
```
@article{jiang2023minimax,
title={minimax: Efficient Baselines for Autocurricula in JAX},
author={Jiang, Minqi and Dennis, Michael and Grefenstette, Edward and Rocktäschel, Tim},
booktitle={Agent Learning in Open-Endedness Workshop at NeurIPS},
year={2023}
}
```
The original readme is included below.
Original Minimax Readme
Efficient baselines for autocurricula in JAX
## Contents
- [Why `minimax`?](#-why-minimax)
- [Hardware-accelerated baselines](#-hardware-accelerated-baselines)
- [Install](#%EF%B8%8F-install)
- [Quick start](#-quick-start)
- [Dive deeper](#-dive-deeper)
- [Training](#training)
- [Logging](#logging)
- [Checkpointing](#checkpointing)
- [Evaluating](#evaluating)
- [Environments](#%EF%B8%8F-environments)
- [Supported environments](#supported-environments)
- [Adding environments](#adding-environments)
- [Agents](#-agents)
- [Roadmap](#-roadmap)
- [License](#-license)
- [Citation](#-citation)
## 🐢 Why `minimax`?
Unsupervised Environment Design (UED) is a promising approach to generating autocurricula for training robust deep reinforcement learning (RL) agents. However, existing implementations of common baselines require excessive amounts of compute. In some cases, experiments can require more than a week to complete using V100 GPUs. **This long turn-around slows the rate of research progress in autocuriculum methods**. `minimax` provides fast, [JAX-based](https://github.com/google/jax) implementations of key UED baselines, which are based on the concept of _minimax_ regret. By making use of fully-tensorized environment implementations, `minimax` baselines are fully-jittable and thus take full advantage of the hardware acceleration offered by JAX. In timing studies done on V100 GPUs and Xeon E5-2698 v4 CPUs, we find `minimax` baselines can run **over 100x faster than previous reference implementations**, like those in [facebookresearch/dcd](https://github.com/facebookresearch/dcd).
All autocurriculum algorithms implemented in `minimax` also support multi-device training, which can be activated through a [single command line flag](#multi-device-training). Using multiple devices for training can lead to further speed ups and allows scaling these autocurriculum methods to much larger batch sizes.
### 🐇 Hardware-accelerated baselines
`minimax` includes JAX-based implementations of
- [Domain Randomization (DR)](https://arxiv.org/abs/1703.06907)
- [Minimax adversary](https://arxiv.org/abs/2012.02096)
- [PAIRED](https://arxiv.org/abs/2012.02096)
- [Population PAIRED](https://arxiv.org/abs/2012.02096)
- [Prioritized Level Replay (PLR)](https://arxiv.org/abs/2010.03934)
- [Robust Prioritized Level Replay (PLR$`^{\perp}`$)](https://arxiv.org/abs/2110.02439)
- [ACCEL](https://arxiv.org/abs/2203.01302)
Additionally, `minimax` includes two new variants of PLR and ACCEL that further reduce wall time by better leveraging the massive degree of environment parallelism enabled by JAX:
- Parallel PLR (PLR$`^{||}`$)
- Parallel ACCEL (ACCEL$`^{||}`$)
In brief, these two new algorithms collect rollouts for new level evaluation, level replay, and, in the case of Parallel ACCEL, mutation evaluation, all in parallel (i.e. rather than sequentially, as done by Robust PLR and ACCEL). As a simple example for why this parallelization improves wall time, consider how Robust PLR with replay probability of `0.5` would require approximately 2x as many rollouts in order to reach the same number of RL updates as a method like DR, because updates are only performed on rollouts based on level replay. Parallelizing level replay rollouts alongside new level evaluation rollouts by using 2x the environment parallelism reduces the total number of parallel rollouts to equal the total number of updates desired, thereby matching the 1:1 rollout to update ratio of DR. The diagram below summarizes this difference.
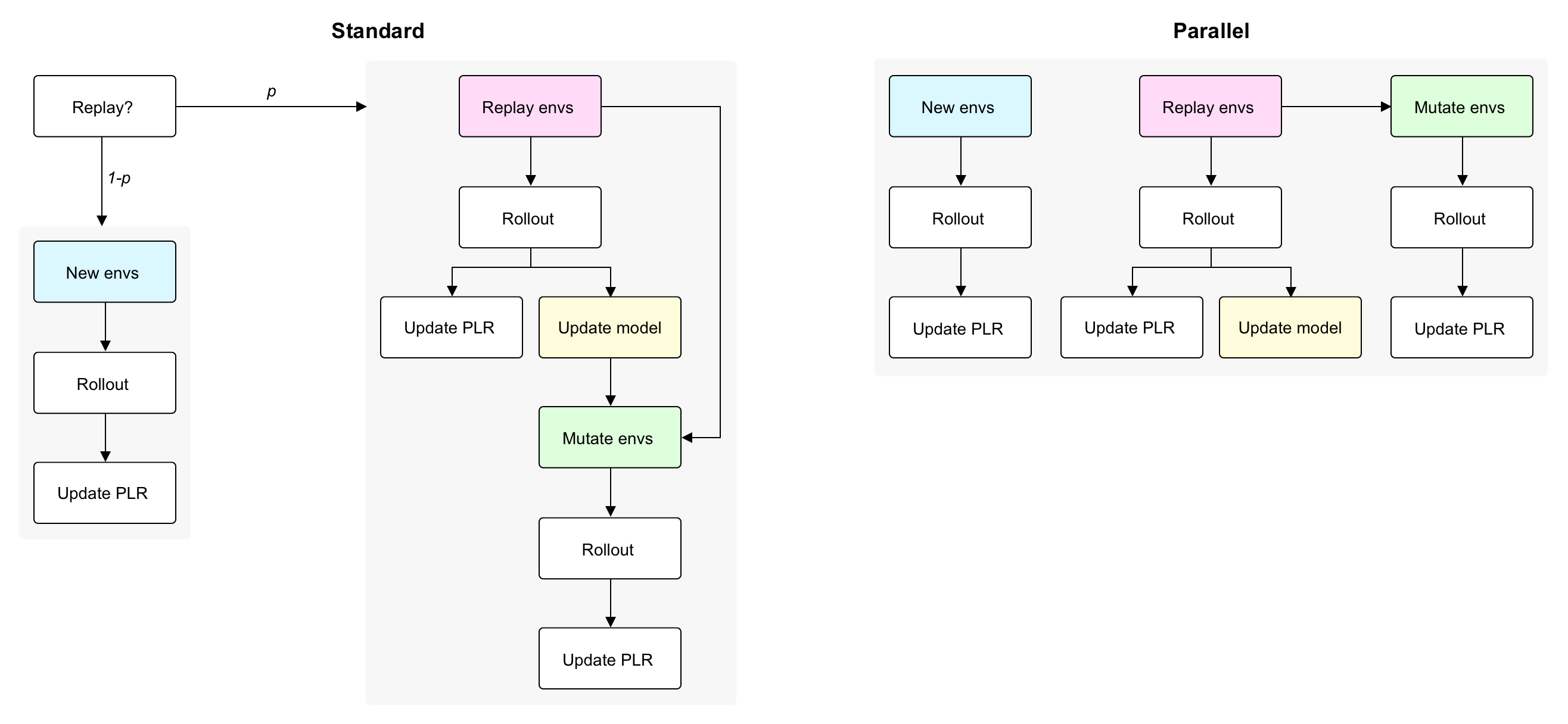
`minimax` includes a fully-tensorized implementation of a maze environment that we call [`AMaze`](docs/envs/maze.md). This environment exactly reproduces the MiniGrid-based mazes used in previous UED studies in terms of dynamics, reward function, observation space, and action space, while running many orders of magnitude faster in wall time, with increasing environment parallelism.
## 🛠️ Install
1. Use a virtual environment manager like `conda` or `mamba` to create a new environment for your project:
```bash
conda create -n minimax
conda activate minimax
```
2. Install `minimax` via either `pip install minimax-lib` or `pip install ued`.
3. That's it!
⚠️ Note that to enable hardware acceleration on GPU, you will need to make sure to install the latest version of `jax>=0.4.19` and `jaxlib>=0.4.19` that is compatible with your CUDA driver (requires minimum CUDA version of `11.8`). See [the official JAX installation guide](https://jax.readthedocs.io/en/latest/installation.html#pip-installation-gpu-cuda-installed-via-pip-easier) for detailed instructions.
## 🏁 Quick start
The easiest way to get started is to play with the Python notebooks in the [examples folder](examples) of this repository. We also host Colab versions of these notebooks:
- DR [[IPython](examples/dr.ipynb), [Colab](https://colab.research.google.com/drive/1HhgQgcbt77uEtKnV1uSzDsWEMlqknEAM)]
- PAIRED [[IPython](examples/paired.ipynb), [Colab](https://colab.research.google.com/drive/1NjMNbQ4dgn8f5rt154JKDnXmQ1yV0GbT?usp=drive_link)]
- PLR and ACCEL*: [[IPython](examples/plr.ipynb), [Colab](https://colab.research.google.com/drive/1XqVRgcIXiMDrznMIQH7wEXjGZUdCYoG9?usp=drive_link)]
*Depending on how the top-level flags are set, this notebook runs PLR, Robust PLR, Parallel PLR, ACCEL, or Parallel ACCEL.
`minimax` comes with high-performing hyperparameter configurations for several algorithms, including domain randomization (DR), PAIRED, PLR, and ACCEL for 60-block mazes. You can train using these settings by first creating the training command for executing `minimax.train` using the convenience script [`minimax.config.make_cmd`](docs/make_cmd.md):
`python -m minimax.config.make_cmd --config maze/[dr,paired,plr,accel] | pbcopy`,
followed by pasting and executing the resulting command into the command line.
[See the docs](docs/make_cmd.md) for `minimax.config.make_cmd` to learn more about how to use this script to generate training commands from JSON configurations. You can browse the available JSON configurations for various autocurriculum methods in the [configs folder](config/configs).
Note that when logging and checkpointing are enabled, the main `minimax.train` script outputs this data as `logs.csv` and `checkpoint.pkl` respectively in an experiment directory located at `/`, where `log_dir` and `xpid` are arguments specified in the command. You can then evaluate the checkpoint by using `minimax.evaluate`:
```bash
python -m minimax.evaluate \
--seed 1 \
--log_dir \
--xpid_prefix