OLViT: Multi-Modal State Tracking via Attention-Based Embeddings for Video-Grounded Dialog
**[Adnen Abdessaied][4], [Manuel von Hochmeister][5], [Andreas Bulling][6]**
**COLING 2024**, Turin, Italy

**[[Paper][7]]**
----------------

# Table of Contents
* [Setup and Dependencies](#Setup-and-Dependencies)
* [Download Data](#Download-Data)
* [Training](#Training)
* [Testing](#Testing)
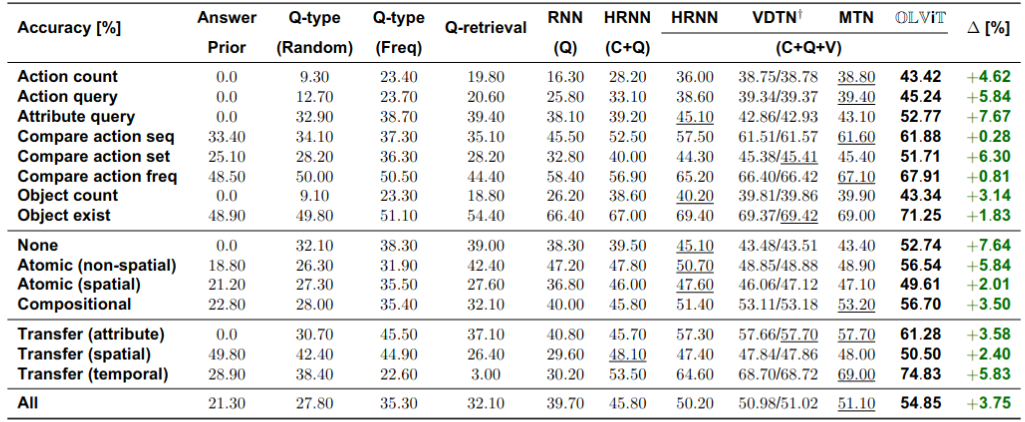
* [Results](#Results)
* [Acknowledgements](#Acknowledgements)
# Setup and Dependencies
We implemented our model using Python 3.7, PyTorch 1.11.0 (CUDA 11.3, CuDNN 8.3.2) and PyTorch Lightning. We recommend to setup a virtual environment using Anaconda.