| .vscode | ||
| docs | ||
| src | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| requirements.txt | ||
The Overcooked Generalisation Challenge

This repository houses the Overcooked generalisation challange, a novel cooperative UED environment that explores the effect of generalisation on cooperative agents with a focus on zero-shot cooperation. We built this work on top of minimax (original README included below) and are inspired by many of their implementation details.
We require Python to be above 3.9 and below 3.12, we use 3.10.12.
To install this research code use pip install -r requirements.txt.
Structure
Our project inlcudes the following major components:
- Overcooked UED
- Multi-Agent UED Runners
- Scripts for training and evaluations
- Holdout populations for evaluation (accesible here)
We highlight our additions to minimax below often with additional comments. We choose minimax as the basis as it is tested and intended for this use case. The project is structured as follows:
docs/
envs/
...
overcooked.md (<- We document OvercookedUED here)
images/
...
examples/*
src/
config/
configs/
maze/*
overcooked/* (<- Our configurations for all runs in the paper)
minimax/
agents/
...
mappo.py (<- Our MAPPO interface for training)
config/* (<- logic related to configs, and getting commands, OvercookedUED included)
envs/
...
overcooked_proc/ (<- home of overcooked procedual content generation for UED)
...
overcooked_mutators.py (<- For ACCEL)
overcooked_ood.py (<- Testing layouts (can be extended!))
overcooked_ued.py (<- UED interface)
overcooked.py (<- Overcooked capable of being run in parallel across layouts)
models/
...
overcooked/
...
models.py (<- Models we use in the paper are defined here)
runners/*
runners_ma/* (<- multi-agent runners for Overcooked UED and potentially others)
tests/*
utils/*
arguments.py
count_params.py
evaluate_against_baseline.py
evaluate_against_population.py
evaluate_baseline_against_population.py
evaluate_from_pckl.py
evaluate.py
extract_fcp.py
train.py (<- minimax starting point, also for our work)
populations/
fcp/* (see below)
baseline_train__${what} (Trains multiple self play agents across seeds)
eval_xpid_${what} (Evals populations, stay and random agents)
eval_xpid.sh (Evals a run based on its XPID)
extract_fcp.sh (Extracts FCP checkpoint from self-play agents)
make_cmd.sh (Extended with our work)
train_baseline_${method}_${architecture}.sh (Trains all methods in the paper)
train_maze_s5.sh
train_maze.sh
Overcooked UED
We provide a detailed explanation of the environment in the paper. OvercookedUED provides interfaces to both edit-based, generator-based and curator-based DCD methods. For an overview see the figure above.
Mutli-Agent UED Runners
Multi-Agent runners are placed under src/minimax/runners_ma.
They extend the minimax runners by support for multiple agents, i.e. by carrying around hidden states etc.
Note: Our current implementation only features two agents.
Scripts
Reproducability is important to us.
We thus store all important script in this repository that produce the policies discussed in the paper.
To generate a command, please use make_cmd.sh like so by specifying overcooked and the config file name:
> ./make_cmd.sh overcooked baseline_dr_softmoe_lstm
python -m train \
--seed=1 \
--agent_rl_algo=ppo \
--n_total_updates=30000 \
--train_runner=dr \
--n_devices=1 \
--student_model_name=default_student_actor_cnn \
--student_critic_model_name=default_student_critic_cnn \
--env_name=Overcooked \
--is_multi_agent=True \
--verbose=False \
--log_dir=~/logs/minimax \
--log_interval=10 \
--from_last_checkpoint=False \
...
They are named train_baseline_${method}_${architecture}.sh and can be found in src.
${method} specifies the DCD method and can be from {p_accel, dr, pop_paired, p_plr} which correspond to parallel ACCEL (https://arxiv.org/abs/2203.01302 & https://arxiv.org/abs/2311.12716), domain randimisation (https://arxiv.org/abs/1703.06907), population paired (https://arxiv.org/abs/2012.02096) and parallel PLR (https://arxiv.org/abs/2010.03934 & https://arxiv.org/abs/2311.12716).
${architecture} on the other hand corresponds to the neural network architechture employed and can be from {lstm, s5, softmoe}.
To use them, please set the environment variable ${WANDB_ENTITY} to your wandb user name or specify wandb_mode=offline.
The scripts can be called like this:
./train_baseline_p_plr_s5.sh $device $seed
The scripts run src/minimax/train.py and store their results to the configured locations (see the config jsons and the --log_dir flag) but usually somewhere in your home directory ~/logs/.
There are 12 train scripts and helper scripts that run multiple variations of these after the other, i.e. like in train_baselines_s56x9.sh that trains all 4 DCD methods with an S5 policy:
DEFAULTVALUE=4
DEFAULTSEED=1
device="${1:-$DEFAULTVALUE}"
seed="${2:-$DEFAULTSEED}"
echo "Using device ${device} and seed ${seed}"
./train_baseline_p_plr_s5.sh $device $seed
./train_baseline_p_accel_s5.sh $device $seed
./train_baseline_pop_paired_s5.sh $device $seed
./train_baseline_dr_s5.sh $device $seed
Evaluation is performed via scripts starting with eval.
One can evaluate against scripted agents eval_stay_against_population.sh and random ones via eval_random_against_population.sh.
To evaluate against a population using a trained agent use eval_xpid_against_population.sh with device 4 and the agents XPID YOUR_XPID you can use ./eval_xpid_against_population.sh 4 YOUR_XPID.
Holdout populations for evaluation
The populations can be accessed here: https://drive.google.com/drive/folders/11fxdhrRCSTmB7BvfqMGqdIhvJUDv_0zP?usp=share_link.
They need to be placed under src/populations to work with the provided scripts.
Alternatively -- if desired -- populations can be obtained by running src/baseline_train__all.sh or alternatively by using src/baseline_train__8_seeds.sh for the desired layout, i.e. via:
./baseline_train__8_seeds.sh $device coord_ring_6_9
We exclude the detailed calls here as they are too verbose. The resulting directory structure for inlcuding the poppulations should look like the following:
src/
minimax
...
populations/
fcp/
Overcooked-AsymmAdvantages6_9/
1/
high.pkl
low.pkl
meta.json
mid.pkl
xpid.txt
2/*
...
8/*
population.json
Overcooked-CoordRing6_9/*
Overcooked-CounterCircuit6_9/*
Overcooked-CrampedRoom6_9/*
Overcooked-ForcedCoord6_9/*
To work with these populations meta files point to the correct scripts.
These are included in the downloadable zip, called population.json (see above) and should look like this:
{
"population_size": 24,
"1": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/low.pkl",
"2": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/mid.pkl",
...
"24": "populations/fcp/Overcooked-AsymmAdvantages6_9/8/high.pkl",
"1_meta": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/meta.json",
"2_meta": "populations/fcp/Overcooked-AsymmAdvantages6_9/1/meta.json",
...
"24_meta": "populations/fcp/Overcooked-AsymmAdvantages6_9/8/meta.json"
}
They help our evaluation to keep track of the correct files to use.
To check whether they work correctly use something along the lines of (compare the eval scripts):
DEFAULTVALUE=4
device="${1:-$DEFAULTVALUE}"
for env in "Overcooked-CoordRing6_9" "Overcooked-ForcedCoord6_9" "Overcooked-CounterCircuit6_9" "Overcooked-AsymmAdvantages6_9" "Overcooked-CrampedRoom6_9";
do
CUDA_VISIBLE_DEVICES=${device} LD_LIBRARY_PATH="" nice -n 5 python3 -m minimax.evaluate_baseline_against_population \
--env_names=${env} \
--population_json="populations/fcp/${env}/population.json" \
--n_episodes=100 \
--is_random=True
done
Credit the minimax authors
For attribution in academic contexts please also cite the original work on minimax:
@article{jiang2023minimax,
title={minimax: Efficient Baselines for Autocurricula in JAX},
author={Jiang, Minqi and Dennis, Michael and Grefenstette, Edward and Rocktäschel, Tim},
booktitle={Agent Learning in Open-Endedness Workshop at NeurIPS},
year={2023}
}
The original readme is included below.
Original Minimax Readme
Efficient baselines for autocurricula in JAX
![]()
![]()
![]()
![]()
Contents
🐢 Why minimax?
Unsupervised Environment Design (UED) is a promising approach to generating autocurricula for training robust deep reinforcement learning (RL) agents. However, existing implementations of common baselines require excessive amounts of compute. In some cases, experiments can require more than a week to complete using V100 GPUs. This long turn-around slows the rate of research progress in autocuriculum methods. minimax provides fast, JAX-based implementations of key UED baselines, which are based on the concept of minimax regret. By making use of fully-tensorized environment implementations, minimax baselines are fully-jittable and thus take full advantage of the hardware acceleration offered by JAX. In timing studies done on V100 GPUs and Xeon E5-2698 v4 CPUs, we find minimax baselines can run over 100x faster than previous reference implementations, like those in facebookresearch/dcd.
All autocurriculum algorithms implemented in minimax also support multi-device training, which can be activated through a single command line flag. Using multiple devices for training can lead to further speed ups and allows scaling these autocurriculum methods to much larger batch sizes.
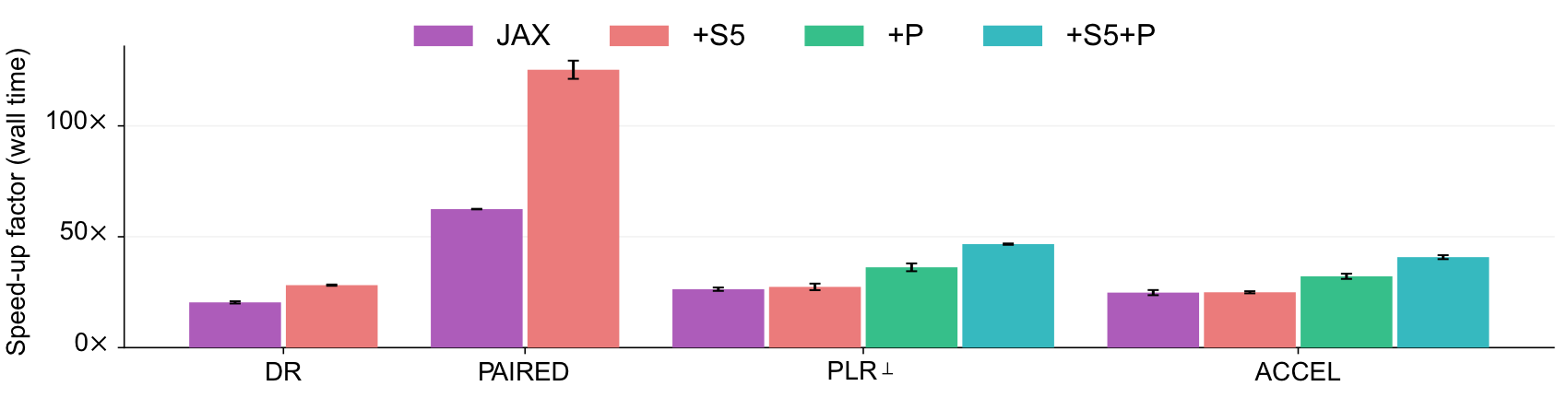
🐇 Hardware-accelerated baselines
minimax includes JAX-based implementations of
Additionally, minimax includes two new variants of PLR and ACCEL that further reduce wall time by better leveraging the massive degree of environment parallelism enabled by JAX:
-
Parallel PLR (PLR$
^{||}$) -
Parallel ACCEL (ACCEL$
^{||}$)
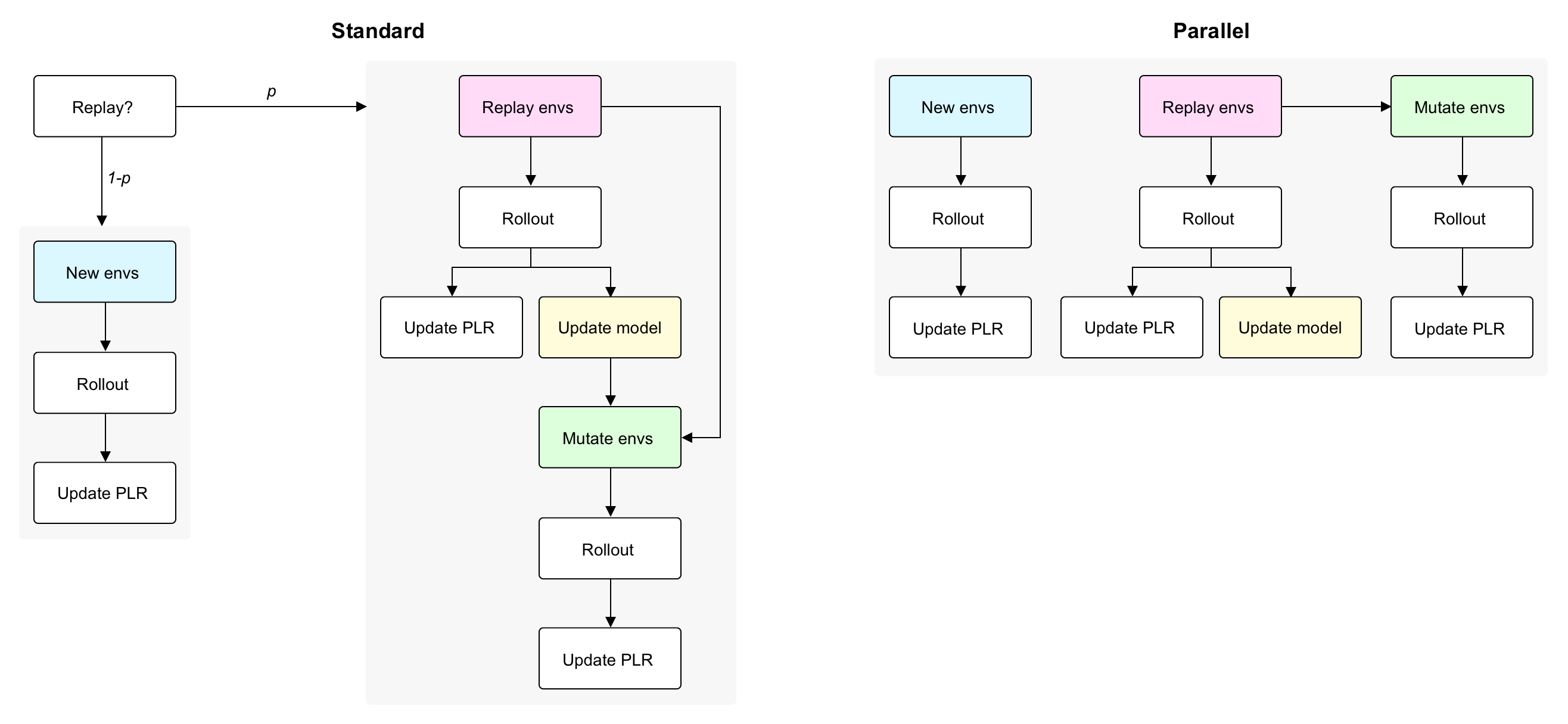
In brief, these two new algorithms collect rollouts for new level evaluation, level replay, and, in the case of Parallel ACCEL, mutation evaluation, all in parallel (i.e. rather than sequentially, as done by Robust PLR and ACCEL). As a simple example for why this parallelization improves wall time, consider how Robust PLR with replay probability of 0.5 would require approximately 2x as many rollouts in order to reach the same number of RL updates as a method like DR, because updates are only performed on rollouts based on level replay. Parallelizing level replay rollouts alongside new level evaluation rollouts by using 2x the environment parallelism reduces the total number of parallel rollouts to equal the total number of updates desired, thereby matching the 1:1 rollout to update ratio of DR. The diagram below summarizes this difference.
minimax includes a fully-tensorized implementation of a maze environment that we call AMaze. This environment exactly reproduces the MiniGrid-based mazes used in previous UED studies in terms of dynamics, reward function, observation space, and action space, while running many orders of magnitude faster in wall time, with increasing environment parallelism.
🛠️ Install
- Use a virtual environment manager like
condaormambato create a new environment for your project:
conda create -n minimax
conda activate minimax
-
Install
minimaxvia eitherpip install minimax-liborpip install ued. -
That's it!
⚠️ Note that to enable hardware acceleration on GPU, you will need to make sure to install the latest version of jax>=0.4.19 and jaxlib>=0.4.19 that is compatible with your CUDA driver (requires minimum CUDA version of 11.8). See the official JAX installation guide for detailed instructions.
🏁 Quick start
The easiest way to get started is to play with the Python notebooks in the examples folder of this repository. We also host Colab versions of these notebooks:
*Depending on how the top-level flags are set, this notebook runs PLR, Robust PLR, Parallel PLR, ACCEL, or Parallel ACCEL.
minimax comes with high-performing hyperparameter configurations for several algorithms, including domain randomization (DR), PAIRED, PLR, and ACCEL for 60-block mazes. You can train using these settings by first creating the training command for executing minimax.train using the convenience script minimax.config.make_cmd:
python -m minimax.config.make_cmd --config maze/[dr,paired,plr,accel] | pbcopy,
followed by pasting and executing the resulting command into the command line.
See the docs for minimax.config.make_cmd to learn more about how to use this script to generate training commands from JSON configurations. You can browse the available JSON configurations for various autocurriculum methods in the configs folder.
Note that when logging and checkpointing are enabled, the main minimax.train script outputs this data as logs.csv and checkpoint.pkl respectively in an experiment directory located at <log_dir>/<xpid>, where log_dir and xpid are arguments specified in the command. You can then evaluate the checkpoint by using minimax.evaluate:
python -m minimax.evaluate \
--seed 1 \
--log_dir <absolute path log directory> \
--xpid_prefix <select checkpoints with xpids matching this prefix> \
--env_names <csv string of test environment names> \
--n_episodes <number of trials per test environment> \
--results_path <path to results folder> \
--results_fname <filename of output results csv>
🪸 Dive deeper
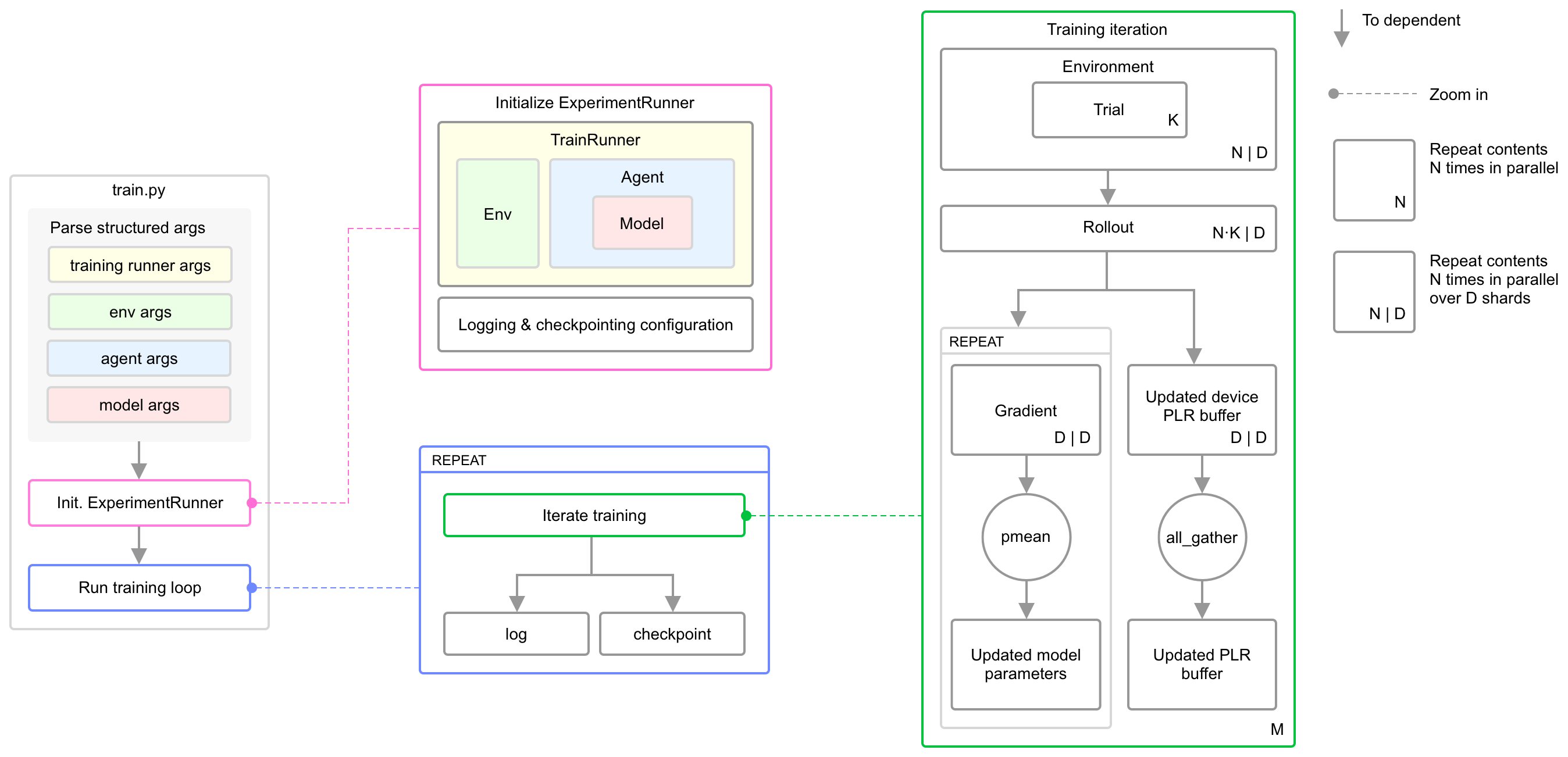
Training
The main entry for training is minimax.train. This script configures the training run based on command line arguments. It constructs an instance of ExperimentRunner to manage the training process on an update-cycle basis: These duties include constructing and delegating updates to an appropriate training runner for the specified autocurriculum algorithm and conducting logging and checkpointing. The training runner used by ExperimentRunner executes all autocurriculum-related logic. The system diagram above describes how these pieces fit together, as well as how minimax manages various, hierarchical batch dimensions.
Currently, minimax includes training runners for the following classes of autocurricula:
| Runner | Algorithm class | --train_runner |
|---|---|---|
DRRunner |
Domain randomization | dr |
PLRRunner |
Replay-based curricula, including ACCEL | plr |
PAIREDRunner |
Curricula via a co-adapting teacher environment design policy | paired |
The below table summarizes how various autocurriculum methods map to these runners and the key arguments that must be set differently from the default settings in order to switch the runner's behavior to each method.
| Algorithm | Reference | Runner | Key args |
|---|---|---|---|
| DR | Tobin et al, 2019 | DRRunner |
– |
| Minimax adversary | Dennis et al, 2020 | PAIREDRunner |
ued_score='neg_return' |
| PAIRED | Dennis et al, 2020 | PAIREDRunner |
– |
| Population PAIRED | Dennis et al, 2020 | PAIREDRunner |
n_students >= 2, ued_score='population_regret' |
| PLR | Jiang et al, 2021 | PLRRunner |
plr_use_robust_plr=False |
| Robust PLR | Jiang et al, 2021a | PLRRunner |
– |
| ACCEL | Parker-Holder et al, 2022 | PLRRunner |
plr_mutation_fn != None, plr_n_mutations > 0 |
| Parallel PLR | Jiang et al, 2023 | PLRRunner |
plr_use_parallel_eval=True |
| Parallel ACCEL | Jiang et al, 2023 | PLRRunner |
plr_use_parallel_eval=True, plr_mutation_fn != None, plr_n_mutations > 0 |
See the docs on minimax.train for a comprehensive guide on how to configure command-line arguments for running various autocurricula methods via minimax.train.
Logging
By default, minimax.train generates a folder in the directory specified by the --log_dir argument, named according to --xpid. This folder contains the main training logs, logs.csv, which are updated with a new row every --log_interval rollout cycles.
Checkpointing
Latest checkpoint:
The latest model checkpoint is saved as checkpoint.pkl. The model is checkpointed every --checkpoint_interval number of updates, where each update corresponds to a full rollout and update cycle for each participating agent. For the same number of environment interaction steps, methods may differ in the number of gradient updates performed by participating agents, so checkpointing based on number of update cycles controls for this potential discrepency. For example, methods based on Robust PLR, like ACCEL, do not perform student gradient updates every rollout cycle.
Archived checkpoints:
Separate archived model checkpoints can be saved at specific intervals by specifying a positive value for the argument --archive_interval. For example, setting --archive_interval=1000 will result in saving model checkpoints every 1000 updates, named checkpoint_1000.tar, checkpoint_2000.tar, and so on. These archived models are saved in addition to checkpoint.pkl, which always stores the latest checkpoint, based on --checkpoint_interval.
Evaluating
Once training completes, you can evaluate the resulting checkpoint.pkl on test environments using minimax.evaluate. This script can evaluate an individual checkpoint or group of checkpoints created via training runs with a shared experiment ID prefix (--xpid value), e.g. each corresponding to different training seeds of the same experiment configuration. Each checkpoint is evaluated over --n_episodes episodes for each of the test environments, specified via a csv string of test environment names passed in via --env_names. The evaluation results can be optionally written to a csv file in --results_path, if a --results_fname is provided.
See the docs on minimax.evaluation for a comprehensive guide on how to configure command line arguments for minimax.evaluate.
Multi-device training
All autocurriculum algorithms in minimax support multi-device training via shmap across the environment batch dimension (see the system diagram above). In order to shard rollouts and gradient updates along the environment batch dimension across N devices, simply pass minimax.train the additional argument --n_devices=N. By default, n_devices=1.
🏝️ Environments
Supported environments

minimax currently includes AMaze, a fully-tensorized implementation of the partially-observable maze navigation environments featured in previous UED studies (see example AMaze environments in the figure above). The minimax implementation of the maze environment fully replicates the original MiniGrid-based dynamics, reward functions, observation space, action space. See the environment docs fo more details.
We look forward to working with the greater RL community in continually expanding the set of environments integrated with minimax.
Adding environments
In order to integrate into minimax's fully-jittable training logic, environments should be implemented in a tensorized fashion via JAX. All environments must implement the Environment interface. At a high level, Environment subclasses should implement reset and step logic assuming a single environment instance (no environment parallelism). Parallelism is automatically achieved via the training runner logic included withminimax (See the paper and system diagram above for a quick overview of how this is performed).
A key design decision of minimax is to separate environment parameters into two groups:
-
Static parameters are fixed throughout training. These parameters are frozen hyperparameters defining some unchanging aspect of the underlying environment distribution, e.g. the width, height, or maximum number of walls of maze environments considered during training. These static parameters are encapsulated in an
EnvParamsdataclass. -
Free parameters can change per environment instance (e.g. across each instance in a parallel rollout batch). These parameters might correspond to aspects like the specific wall map defining the maze layout or the starting position of the agent. Free parameters are simply treated as part of the fully-traceable
EnvState, taking the form of an arbitrary pytree.
All environments supporting the Environment interface will interoperate with DRRunner and PLRRunner (though for ACCEL mode, where mutation_fn != None, a mutation operator must additionally be defined).
Environment design with a co-adapting teacher policy
In PAIRED-style autocurricula, a teacher policy generates environment instances in order to maximize some curriculum objective, e.g. relative regret. The teacher's decision-making process corresponds to its own MDP.
To support such autocurricula, minimax follows the pattern of implementing separate Environment subclasses for each of student and teacher MDPs. A convenience class called UEDEnvironment is then initialized with instances of the student and teacher MDPs. The UEDEnvironment instance exposes a unified interface for resetting and stepping the teacher and student, which is then used in the training runner. For example, stepping the UEDEnvironment instance for the teacher (via the step_teacher method) produces an environment instance, which can then be used with the reset_student method to reset the state of the UEDEnvironment object to that particular environment instance. Subsequent calls of the step_student method then operate within this environment instance. Following this pattern, integration of a new environment with PAIREDRunner requires implementing the corresponding Environment subclass for the teacher MDP (the decision process ). See minimax/envs/maze/maze_ued.py for an example based on the maze environment.
Environment operators
Custom environment operators can also be defined in minimax.
-
Comparators take two environment instances, as represented by their
EnvStatepytrees and returnTrueiff the two instances are deemed equal. If a comparator is registered for an environment, training runners can use the comparator to enforce uniqueness of environment instances for many purposes, e.g. making sure the members of the PLR buffer are all unique. -
Mutators take an environment instance, as represented by an
EnvStatepytree, and apply some modification to the instance, returning the modified (or "mutated") instance. Mutators are used by ACCEL to mutate environment instances in the PLR buffer. New environments seeking integration with the ACCEL mode of thePLRRunnershould implement and register a default mutation operator.
Registration
Each new Environment subclass should be registered with the envs module:
-
Student environments should be registered using
envs.registration.register. See src/minimax/maze/maze.py for an example. -
Teacher environments should be registered using
envs.registration.register_ued. Seeenvs/maze/maze_ued.pyfor an example. -
Mutators should be registered using
envs.registration.register_mutator. Seeenvs/maze/maze_mutators.pyfor an example. -
Comparators should be registered using
envs.registration.register_comparator. Seeenvs/maze/maze_comparators.pyfor an example.
🤖 Agents
In minimax agents correspond to a particular data-seeking learning algorithm, e.g. PPO. A model corresponds to a module that implements the policy (or value function) used by the agent. Any agent that follows the Agent interface should be usable in any minimax compatible environment.
Model forward passes are assumed to return a tuple of (value_prediction, policy_logits, carry).
Registration
Custom model classes should be registered for a particular environment for which they are designed. See models/maze/gridworld_models.py for an example. After registration, the model can be easily retrieved and via models.make(env_name, model_name, **model_kwargs).
🚀 Roadmap
Many exciting features are planned for future releases of minimax. Features planned for near-term release include:
- Add support for JaxMARL (multi-agent RL environments) via an IPPO mode in
DRRunnerandPLRRunner. - Extend
Parsnipwith methods for composing argument specs across multiple files to reduce the size ofarguments.pycurrently used fortrain.py. - Add support for Jumanji (combinatorial optimization environments), via an appropriate decorator class.
You can suggest new features or ways to improve current functionality by creating an issue in this repository.
🪪 License
minimax is licensed under Apache 2.0.
📜 Citation
For attribution in academic contexts, please cite this work as
@article{jiang2023minimax,
title={minimax: Efficient Baselines for Autocurricula in JAX},
author={Jiang, Minqi and Dennis, Michael and Grefenstette, Edward and Rocktäschel, Tim},
booktitle={Agent Learning in Open-Endedness Workshop at NeurIPS},
year={2023}
}